


最近在写一个爬虫,一个程序去采集需要爬的页面URL然后放置到rabbitMQ队列中,然后启用多个消费者去爬取内容,由于使用代理去爬取,每个消费者处理的时间都会是不一样的。
生产URL的程序非常快的就会生产大量的URL,为了控制rabbitMQ内存使用,我控制了生产者的速度。当消息队列中有操作50条未处理时候,生产者就会暂停一段时间。
rabbitmq默认使用的是平均分发队列,来了消息就平均分配给消费者。
由于每个消费者处理的时间可能会不一样,就会出现,很多消息在个别的消费者上,其他消费者会空闲,
解决办法我们就要使用Fair dispatch公平分发策略,始终保持消费一定数量的消息
credentials = pika.PlainCredentials('admin', 'xxxxxxx')
# 连接到rabbitmq服务器
connection = pika.BlockingConnection(pika.ConnectionParameters('127.0.0.1', 5672, '/', credentials))
channel = connection.channel
channel.queue_declare(queue='Kb_number')
channel.basic_qos(prefetch_count=5)
channel.basic_consume(self.RabbitMQ, queue='Kb_number', )
channel.start_consuming()
这样设置后,我们每个消费者都会最多有5个消息
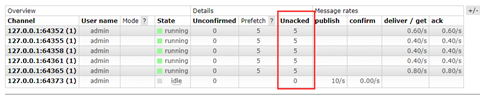
未分配的消息就会在reday状态中

注: 在设置时候遇到的坑
申明basic_qos时一定要在注册consume(basic_consume)之前设置,在之后设置不生效,虽然从控制台上可以看到prefetch有设定的值
文章末尾固定信息

![Django在使用logging日志模块时报错无法操作文件PermissionError: [WinError 32]](https://www.qnjslm.com/wp-content/themes/begin/prune.php?src=https://www.qnjslm.com/wp-content/uploads/2019/02/022419_1331_Djangologgi1.png&w=280&h=210&a=&zc=1)
评论